


Что такое «Королев» и как он эволюционировал из «Палеха»?
Метод «Королев» – логическое продолжение «Палеха», но с вблизи значительных индивидуальностей.
Ведомо, собственно что разведка определяет тему. Человек, как правило, не дает для себя отчета о механизмах, которые задействованы в акте определения темы сообщения. К примеру, затевая речь о предмете в каком-либо контексте, мы можем не именовать его напрямик, а обрисовывать с поддержкой симптомов.
Так, к примеру, услышав «у него удовлетворительной объектив», «зеркалка чем какого-либо другого, чем беззеркалка», «видоискатель в данной модели не нужен», «хорошее фокусное расстояние», мы осознаем, о чем идет речь, но текст «фотоаппарат» проговорено не было.
Мы не осознаем, как это трудится в голове человека. Но для организации информативного и нужного розыска, довольно принципиально внятно представлять эти процессы. В традиционном осознании это трудится так. (Рис.1)

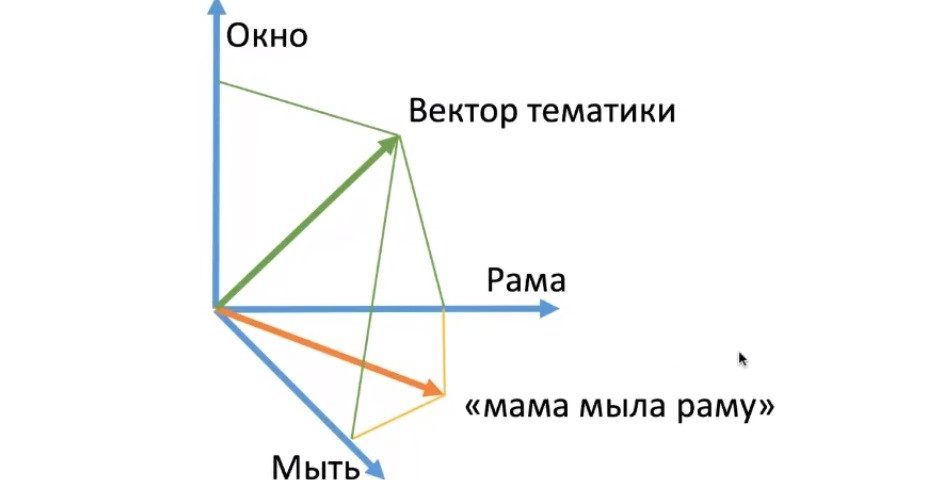
Рис. 1. Пример определения тематики поисковыми системами
Предположим трехмерное место, в котором есть 3 вектора, надлежащие текстам «мыть», «окно» и «рама». Поймем простое школьное предложение: «Мама мыла раму». Абсолютно бесспорно, собственно что наличествует кое-какое соотношение меж вектором темы и текстами «мама», «мыть» и «рама» в данной фразе.
Это очень облегченное представление, как трудится устройство определения темы. И как раз по причине собственной простоты оно содержит ряд значительных ограничений, одним из коих считается:
Большущее численность текстов в российском языке – в пределах 1 000 000.
При этом это, в случае если арестовать лишь только общеупотребительные текста и сначала лематизировать их – привести к исходной словоформе. Это разъясняет низкую скорость вычислений. Для трехмерного места на рис.1 счесть вектор темы просто, но для места в миллион измерений уже довольно с трудом изготовить сопоставление меж векторами.
В следствие этого появилась надобность разработки способов сжатия матрицы. На нынешний денек в SEO ведущими считаются два:
LSI,
Сжатие нейросетями.
К дефектам LSI относят:
Надобность заблаговременно аристократия численность вероятных тем.
Невозможность менять получившееся сжатие, добавлять к нему свежие данные, к примеру, о предпочтениях юзеров.
Вероятность оперировать лишь только группами, а не парами запрос-документ, которые предполагают больший внимание с точки зрения ранжирования.
Нейросети лишены данных дефектов. Кроме сжатия размерности матрицы, они владеют довольно необходимым плюсом – вероятностью ассоциировать различные величины:
Запрос-запрос.
Запрос-заголовок (как делалось в «Палехе»).
Запрос-документ (как делается в «Королеве»).
Необходимым принципным различием всех самообучающихся алгоритмов, и в что количестве нейросетей, считается вероятность решить задачку в будущем, которую мы не знаем, как решить, на этот момент. Мы даем нейросети не строго конкретную программку, мы даем ей район, на которой она обязана станет выучиться – обучающую подборку.
Нейросети состоят из нейронов – особых алгоритмов, которые делают одно несложное воздействие – берут входные данные и складывают их. «Обучение» нейронов случается за счет конфигурации связей меж ними.
Зодчество нейросети подразумевает присутствие:
Входного слоя, куда поступают данные.
Промежного (скрытого) слоя, где происходят вычисления.
Выходного слоя, откуда мы данные получаем

Рис. 2. Архитектура нейросети
Нейросеть умеет очень хорошо сжимать размерность векторного пространства. Миллион слов она вполне способна сжать без потери качества до ста.
Возьмем словосочетание «корова гуляет». Оперировать в поиске можно различными вариантами:
Метод «Королев» оперирует незамедлительно всеми 3-мя пунктами, обучается на пользовательских данных и делает пары векторов, которые затем ассоциирует: вектор запрос с вектором документ.
С сего этапа наступает SEO-мифология. В случае если разведка не оперирует этим мнением, как главное текст, отчего в ТОПе не наличествуют веб-сайты, в коих главных текстов не содержится?
Все довольно элементарно. В розыске есть иерархия ранжирования. Разведка не использует 1 и ту же формулу ко всем документам. В начале он использует элементарно формулу ко всем документам, затем использует формулу посложнее, дабы избрать 100–150 документов, затем избирает из, положим, 100 – 10.
1-ые рубежи ранжирования именовались прежде «прохождением кворума», когда отбираются бумаги, которые в принципе имеют все шансы ответить на задаваемый вопрос из множества млн. или же в том числе и млрд претендентов. И на предоставленном рубеже метод «Королев» НЕ Трудится. То есть он не имеет возможность отнять релевантный документ, в случае если в нем не находится главных текстов. В следствие этого те бумаги, которые наличествуют в ТОПе, например или же по другому станут держать некие ключевые слова, достаточные для прохождения кворума. Это самое неотъемлемое строгое условие.
В следствие этого, когда вы пробуете разбирать выдачу, не надобно пробовать находить веб-сайты без главных текстов. Вы их, быстрее всего, не отыщете, а в случае если и отыщете, то на данный вебсайт станет производить гиперссылка с анкором, содержащим источник.
Стандартная рекомендация: «Продолжайте развивать сайт для пользователей в соответствии с нашими рекомендациями, и со временем он сможет быть представлен в поиске на более высоких позициях» – НЕ РАБОТАЕТ, если вы пытаетесь развивать ресурс без ориентации на поисковую оптимизацию.
Сложности, связанные с учетом предпочтений пользователей
Но не все так плохо! Есть и пара приятных моментов:
Нам нужно из поисковой выдачи взять документы и попробовать опереться на то, как эти документы отранжированы, (но не слишком сильно, потому что сигнал «Королева» на данный момент достаточно слабый) и попытаться представить их в понятном для человека виде.
Людям трудно оперировать буквенными триграммами и отдельно взятыми словами, вырванными из контекста, нужно делать минимум биграммы. Но данный процесс можно автоматизировать, например, с помощью инструмента «Акварель».

Рис. 3. Технические вектора на основе алгоритма «Акварели»
Он разбирает слова документа вниз до сотого, цепляет дополнительные документы из коллекции, которые похожи по своему словарному составу, ведет учет межсловных расстояний. В результате получается достаточно хороший тематический вектор. Использовать можно разные инструменты, важно проводить эту работу, так как с нарастанием влияния «Королева», по моей оценке, это будет схожим по значимости фактором ранжирования вместе с вхождением ключевых слов.

Рис. 4. Разметка документа на медианную тематичность слова
На рис. 4 показана разметка документа на так называемую медианную тематичность слова. Для каждого отдельного слова была просчитана тематичность векторов запроса (т.е. для каждого запроса был составлен тематический вектор), посчитана релевантность каждого отдельного слова и представлена в виде графика, то есть насколько этот показатель зависит от позиций. Оказалось, что зависимость есть, и наиболее ярко она выражена в ТОП 10. За пределами «заветной десятки» ее практически нет. Причем наиболее заметно это явление выражено среди информационных запросов.
Что следует запомнить?
«Баден» интересен тем, что он учитывает сразу несколько показателей и не опирается исключительно на количество вхождений, расчет спамности и т.д. Он работает совокупно. Поэтому анализируя тексты конкурентов, которые обогнали вас в выдаче, нужно учитывать не только ключи и количество их вхождений, но и как минимум – спамность, тематичность и индекс удобочитаемости текста.
Под спамностью подразумевается не количество ключей, которые там используются, а сам характер текста. Индекс удобочитаемости следует использовать в адаптированном виде для русскоязычных текстов. Но «враги» хорошего текста в принципе общие для разных языков – редкие малознакомые слова, длинные предложения.
Не следует делать текст исключительно из тематичных слов без общей лексики. Вопрос в их достаточном количестве. Проверить текста на переизбыток ключей и их синонимов достаточно просто. Нужно удалить их из текста и прочитать результат, если вам по-прежнему понятно, о чем идет речь – текст хороший. Нужно помнить, что оценка тематичности у всех сервисов является субъективной и не копирует поиск, так как не располагает достаточными данными.
Подробно про работу в условиях Королёва и Палеха я буду рассказывать на своем мастер-классе «Продвижение сайта услуг» 7–9 октября в Москве. Основная повестка мероприятия – это продвижение сайтов услуг. Мастер-класс для тех, кто продвигает свои услуги в поисковых системах, например, заказ такси, заказ эвакуаторов, медицинские услуги, стоматология, турагентства и т.д.